Bart Anomation
Bart Anomation
下载安装包
step1:进入brat的主页,下载安装包下载安装包brat-v1.3_Crunchy_Frog.tar.gz。链接为:http://brat.nlplab.org/index.html
Step2:解压后,进行安装
1 | cd brat-v1.3_Crunchy_Frog |
flup python lib
1 | cd server/lib && tar xfz flup-1.0.2.tar.gz |
如果没有apache,安装:
1 | sudo apt-get install apache2 |
修改apache配置:
1 | sudo vim /etc/apache2/apache2.conf |
加入如下语句:
1 | <Directory /home/*/public_html> |
对userdir赋权:
1 | sudo a2enmod userdir |
继续执行:
1 | sudo apt-get install libapache2-mod-fastcgi |
重新加载apache的配置:
1 | sudo /etc/init.d/apache2 reload |
这个时候查看http:127.0.0.1便可以看到apache默认页面。
进入到public_html/brat-v1.3_Crunchy_Frog文件夹,然后:
1 | sudo chgrp -R www-data data work |
安装standalone server
1 | bash install.sh -u |
然后运行服务:
1 | python standalone.py |
出现错误,使用Python2就行
1 | python2 standalone.py |
配置alise替换命令
1 | vim ~/.bashrc |
添加如下命令:
1 | alias cdbrat="cd /usr/local/brat/brat-v1.3_Crunchy_Frog" |
使其生效:
1 | source ~/.bashrc |
下次登录直接使用以下命令
1 | cdbrat && runbrat |
Bert_deploy_for_chinese_classification_task
[转]简单高效的Bert中文文本分类模型开发和部署
1.项目目录路径
![]()

- src/export.sh、src/export.py导出TF serving的模型

src/client.sh、src/client.py、src/file_base_client.py 处理输入数据并向部署的TF serving的模型发出请求,打印输出结果
部署指令:
1
simple_tensorflow_serving --model_base_path="./api"
正常启动终端界面:
浏览器访问界面:
本地请求代码
分为两种,一种是读取文件的,就是要预测的文本是tsv文件的,叫做file_base_client.py,另一个直接输入文本的是client.py。首先更改input_fn_builder,返回dataset,然后从dataset中取数据,转换为list格式,传入模型,返回结果。
正常情况下的运行结果:
chanese_text_analysis
中文文本分类方法
文本分类 = 文本表示 + 分类模型¶
文本表示:BOW/N-gram/TF-IDF/word2vec/word embedding/ELMo
词袋模型(中文):
①分词:
第1句话:[w1 w3 w5 w2 w1…]
第2句话:[w11 w32 w51 w21 w15…]
第3句话…
…
- 载入jieba库,使用jieba.lcut进行分词
1 | df = pd.read_csv("./origin_data/entertainment_news.csv", encoding='utf-8') |
- 去停用词
1 | words_df=pd.DataFrame({'segment':segment}) |
②统计词频:
w3 count3
w7 count7
wi count_i
…
1 | words_stat=words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size}) |
③构建词典:
选出频次最高的N个词
开[1*n]这样的向量空间
(每个位置是哪个词)
1 | dictionary = corpora.Dictionary(sentences) #创建字典 |
④映射:把每句话共构建的词典进行映射
第1句话:[1 0 1 0 1 0…]
第2句话:[0 0 0 0 0 0…1, 0…1,0…]
⑤提升信息的表达充分度:
把是否出现替换成频次
不只记录每个词,我还记录连续的n-gram
- “李雷喜欢韩梅梅” => (“李雷”,”喜欢”,”韩梅梅”)
- “韩梅梅喜欢李雷” => (“李雷”,”喜欢”,”韩梅梅”)
- “李雷喜欢韩梅梅” => (“李雷”,”喜欢”,”韩梅梅”,”李雷喜欢”, “喜欢韩梅梅”)
- “韩梅梅喜欢李雷” => (“李雷”,”喜欢”,”韩梅梅”,”韩梅梅喜欢”,”喜欢李雷”)
不只是使用频次信息,需要知道词对于句子的重要度
TF-IDF = TF(term frequency) + IDF(inverse document frequency)
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
1 | import jieba.analyse as analyse |
⑥上述的表达都是独立表达(没有词和词在含义空间的分布)
喜欢 = 在乎 = “稀罕” = “中意”
- word-net (把词汇根据关系构建一张网:近义词、反义词、上位词、下位词…)
- 怎么更新?
- 个体差异?
- 希望能够基于海量数据的分布去学习到一种表示
- nnlm => 词向量
- word2vec(周边词类似的这样一些词,是可以互相替换,相同的语境)
- 捕捉的是相关的词,不是近义词
- 我 讨厌 你
- 我 喜欢 你
- 捕捉的是相关的词,不是近义词
- word2vec优化…
- 用监督学习去调整word2vec的结果(word embedding/词嵌入)
- 文本预处理
- 时态语态Normalize
- 近义词替换
- stemming
- …
分类模型:NB/LR/SVM/LSTM(GRU)/CNN
语种判断:拉丁语系,字母组成的,甚至字母也一样 => 字母的使用(次序、频次)不一样
对向量化的输入去做建模
①NB/LR/SVM…建模
- 可以接受特别高维度的稀疏表示
②MLP/CNN/LSTM
- 不适合稀疏高维度数据输入 => word2vec
接下来以完成朴素贝叶斯中文分类器项目
数据介绍
选择科技、汽车、娱乐、军事、运动 总共5类文本数据进行处理
1 | import jieba |
数据分析与预处理
- 读取停用词
1 | stopwords=pd.read_csv("origin_data/stopwords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8') |
除去停用词
并且将处理后的数据放到新的文件夹,避免每次重复操作
1 | def preprocess_text(content_lines, sentences, category, target_path): |
- 生成训练集和验证集
先打乱下,生成更可靠的训练集
1 | import random |
原数据集分词训练集和验证集
1 | from sklearn.model_selection import train_test_split |
下一步要做的就是在降噪数据上抽取出来有用的特征啦,我们对文本抽取词袋模型特征
1 | from sklearn.feature_extraction.text import CountVectorizer |
把分类器import进来并且训练
1 | from sklearn.naive_bayes import MultinomialNB |
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
查看准确率
1 | classifier.score(vec.transform(x_test), y_test) |
.8318188045116215
特征工程
我们可以看到在2w多个样本上,我们能在5个类别上达到83%的准确率。
有没有办法把准确率提高一些呢?
我们可以把特征做得更棒一点,比如说,我们试试加入抽取2-gram和3-gram的统计特征,比如可以把词库的量放大一点。
1 | from sklearn.feature_extraction.text import CountVectorizer |
训练结果提升到0.8732818850175808
建模与优化对比
- 交叉验证
更可靠的验证效果的方式是交叉验证,但是交叉验证最好保证每一份里面的样本类别也是相对均衡的,我们这里使用StratifiedKFold
1 | from sklearn.model_selection import StratifiedKFold |
0.8812996456456414
- 换模型/特征试试
1 | from sklearn.svm import SVC |
- rbf核
1 | from sklearn.svm import SVC |
项目最终结果
自定义类,以备后续使用
1 | import re |
Proj1_Language_detector
Language_detector base on ML
项目流程与步骤
是一个有监督的文本分类问题。
读入文件并进行预处理(清洗,分词)
文本进行向量化表示(TF-IDF,BOW,word2vec,word embedding,ELMo…)
建模(机器学习,深度学习方法)
模型封装以备后续使用
项目部署到Web框架(基于Flask)
数据预处理(清洗,分词)
数据读入并查看数据
twitter数据,包含English, French, German, Spanish, Italian 和 Dutch 6种语言
1 | !head -5 data.csv |
1 december wereld aids dag voorlichting in zuidafrika over bieten taboes en optimisme,nl
1 millón de afectados ante las inundaciones en sri lanka unicef está distribuyendo ayuda de emergencia srilanka,es
1 millón de fans en facebook antes del 14 de febrero y paty miki dani y berta se tiran en paracaídas qué harías tú porunmillondefans,es
1 satellite galileo sottoposto ai test presso lesaestec nl galileo navigation space in inglese,it
10 der welt sind bei,de
1 | in_f = open('data.csv') |
[(‘1 december wereld aids dag voorlichting in zuidafrika over bieten taboes en optimisme’,
‘nl’),
(‘1 millón de afectados ante las inundaciones en sri lanka unicef está distribuyendo ayuda de emergencia srilanka’,
‘es’),
(‘1 millón de fans en facebook antes del 14 de febrero y paty miki dani y berta se tiran en paracaídas qué harías tú porunmillondefans’,
‘es’),
(‘1 satellite galileo sottoposto ai test presso lesaestec nl galileo navigation space in inglese’,
‘it’),
(‘10 der welt sind bei’, ‘de’)]
数据集和验证集的拆分
1 | from sklearn.model_selection import train_test_split |
数据清洗
用正则表达式对数据进行去噪处理,主要是清楚网址,@,#等内容
1 | import re |
文本进行向量化表示
(TF-IDF,BOW,word2vec,word embedding,ELMo…)
词频向量化和表示
1 | from sklearn.feature_extraction.text import CountVectorizer |
import 分类器
注意这里分类器拟合需要对vector先进行transform处理
1 | from sklearn.naive_bayes import MultinomialNB #多项式分类器 |
3.3 查看分类效果
1 | classifier.score(vec.transform(x_test), y_test) |
建模(机器学习,深度学习方法)
模型存储
1 | model_path = "model/language_detector.model" |
模型加载
1 | new_language_detector = LanguageDetector() |
使用加载的模型预测
1 | new_language_detector.predict("10 der welt sind bei") |
模型封装以备后续使用
1 | import re |
项目部署到Web框架(基于Flask)
Flask 工具
部署参考文档
ML_Interview_Experience
转自:https://ask.julyedu.com/question/88729
基础知识:
常见算法的推导和特点、常见的特征提取方法、处理过拟合的方法、模型评估、模型集成、常见的网络结构、优化方法、梯度消失和爆炸都必须熟悉。这些都是课上讲到过的,只要多温习几遍也就熟悉了。如果有难点确实没理解的,可以拿时间专门攻克,这样可以增强信心。也可以直接请教别人。
项目方面:
重要的是理解算法原理和思想,能够将现实问题转化为机器学习的问题,不是编程经验。
注意知识的系统性和自己的优势
面试的时候,抓住自己熟悉的问题一定要说透,把相关的都说。这样也能把面试官的注意力吸引过来。同时占用了时间,被问到不熟悉领域的机会就少了。
比如问到xgboost,就从决策树(熵)到xgboost都说,同时还要说boost集成的方法,还可以扩展到其他的集成方法(bagging,stacking),还可以对比各种集成的特点,甚至还可以扩展到神经网络,因为神经网络也可以看作是一种集成。
比如问到词向量或嵌入,就从w2v,glove,elmo,到bert都说一遍。如果时间充裕,可以研究各种表示方法,很有意思的。
比如问到关键词提取,就把tf-idf,textrank,lda,都说一遍。如果还知道其他的关键词提取方法就更好。
总之,要让面试官看到你是系统的理解和掌握了,不是零碎的知识。
总结
传统机器学习一定要掌握:svm、lr、决策树、随机森林、GBDT、xgboost和朴素贝叶斯这些基础知识,最好能手推。
深度学习基本都是:CNN以及卷积的意义、RNN以及RNN的初始化、LSTM、常用激活函数(tanh、relu等)这些原理。
自然语言处理方面:一定要把tfidf、word2vec、注意力机制、transformer都熟悉掌握。最好自己去运行几次
ML_Modeling
基于spark的纽约2013出租费用数据分析与建模
项目流程
- 数据读取、清洗与关联
- 数据探索分析可视化
- 数据预处理与特征工程
- 建模、超参数调优、预测与模型存储
- 模型评估
整个项目会用到很多的spark SQL操作,在大家工业界的实际项目中,除掉spark mllib中默认给到的特征工程模块,我们也会经常用spark SQL来进行特征工程(完成各种统计信息计算与变换)。
数据读取、清洗与关联
1 | #数据注册成视图 |
数据探索分析可视化
1 | #使用SQL做数据分析 |
数据预处理与特征工程
1 | #数据变换与特征工程(类别性可以进行数值序号编码转换OneHotEncoder) |
建模、超参数调优、预测与模型存储
1 | #GBT Regression |
模型评估以及保存加载
1 | #from pyspark.ml import PipelineModel |
基于spark的航班延误数据分析与建模
数据读取、清洗与关联
1 | #数据注册成视图 |
数据探索分析可视化
1 | #单维度和多维度分析 |
数据预处理与特征工程
1 | #过滤非空值 |
建模、超参数调优、预测与模型存储
1 | #RL建模并使用ROC进行评估 |
模型评估以及保存加载
1 | from pyspark.ml import PipelineModel |
###
ML_Interview_100_times
第一章 特征工程
对于一个机器学习问题,数据和特征往往觉得了结果的上限,而模型算、算法的选择及优化则是逐步逼近这个上限,课件特征工程的重要性。
特征工程,对一组原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。
两种数据结构
两种常见的数据结构
- 结构化数据
- 看作关系型数据库的一张表,每一列都有清晰的定义,包含数值型、类别性两种基本类型。
- 非结构化数据
- 包括文本、图形、音频、视频,包含的信息无法用一个简单的数值表示,也没有清晰的定义,每一条的大小各不相同。
01 特征归一化
为了消除数据特征之间的量纲影响,我们需要对特征进行归一化处理。使得不同的指标之间具有可比性。
(1) 线性函数归一化($Min-Max Scaling$)。
归一化公式为:
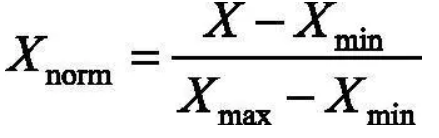
(2) 零均值归一化($Z-Score Normalization$)。将原始数据映射到均值为0,标准差为1的分布。
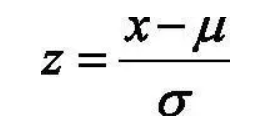
- 结构化数据