Windows下安装hadoop2.7.1
[Windows下安装hadoop2.7.1]https://blog.csdn.net/eagleuniversityeye/article/details/88908074
借助这个blog可以解决:Hadoop集群 启动了之后, ResourceManager未起来的问题
1.安装前需要准备的文件
需要先去官网下载hadoop,但下载完的hadoop是不能直接在Windows上运行的,需要替换bin和etc两个文件夹,替换成专门为Windows下运行而编译的对应版本的bin和etc文件夹
2.配置hadoop环境变量
java的环境变量配置我在这里就不多说了,说下hadoop环境变量配置
右键我的电脑->属性->左边任务栏 高级系统设置->环境变量
在系统变量里新建HADOOP_HOME,设置变量值为hadoop地址
将HADOOP_HOME添加到PATH中,如下图所示
3.修改hadoop配置
第一步:替换文件
将从官网下载的hadoop2.7.1中的bin和etc两个文件夹删除,使用hadooponwindows中的bin和etc代替
第二步:创建缺失的文件夹并将其配置到配置文件中
在hadoop根目录下创建两个文件夹data和tmp
在data文件夹下再创建连个子文件夹datanode和namenode
打开根目录下的etc/hadoop/hdfs-site.xml文件
修改dfs.namenode.name.dir和dfs.datanode.name.dir两个属性的值,改为刚刚创建的两个文件夹datanode和namenode的绝对路径(注意不能直接把在Windows下的路径复制粘贴,路径URL用的是斜杠不是反斜杠,而且前面还要加一个斜杠)然后保存退出
第三步:在hadoop-env.cmd中修改Java虚拟机位置
打开根目录下的etc/hadoop/hadoop-env.cmd文件
找到下图画出的配置,将set JAVA_HOME的值修改为你的Java虚拟机的绝对路径,如果路径中含有Program Files需要用PROGRA~1替换,本人直接安装在D盘的没有空格的文件夹,所以不会遇到该问题
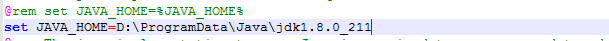
第四步:复制hadoop.dll文件到指定目录
将根目录下的bin文件夹中的hadoop.dll文件复制到C:\Windows\System32文件夹下
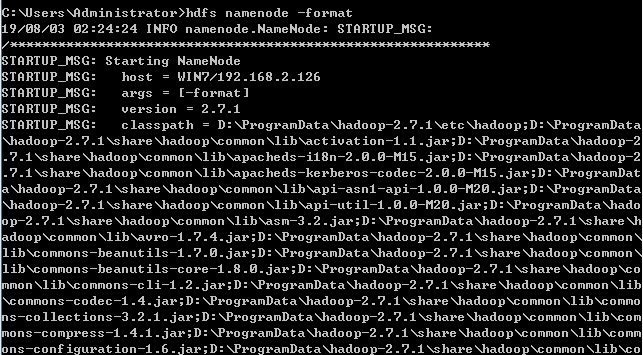
4.测试hadoop使用安装配置成功
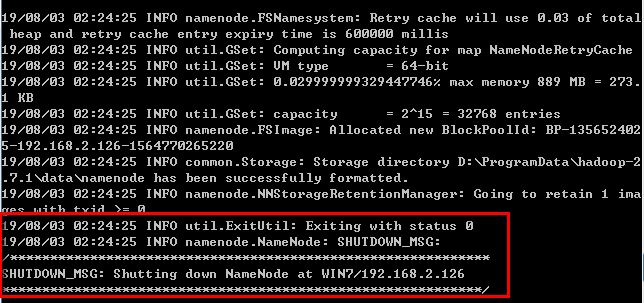
在命令行中输入hdfs namenode -format
等待一会,当命令执行完毕后如果出现如下图二所示的显示,表示hadoop已经安装成功
5.运行
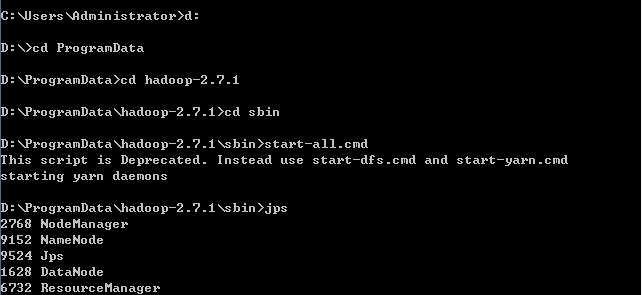
在命令行中进入hadoop根目录下的sbin目录,启动start-all.cmd,接着会弹出四个命令行窗口,输入jps,出现以下显示,说明hadoop运行成功
6 输入stop-all 命令,即可关闭hadoop
Spark RDD & DataFrame
Spark_DataFrame_Exercise_Solution
1 | #初始化 Spark Session |
Note
int的范围
2.7:
32位:-2^312^31-1 64位:-2^632^63-1
3.5:
在3.5中init长度理论上是无限的
2.colab 上配置spark环境
1 | !apt-get install openjdk-8-jdk-headless -qq > /dev/null |